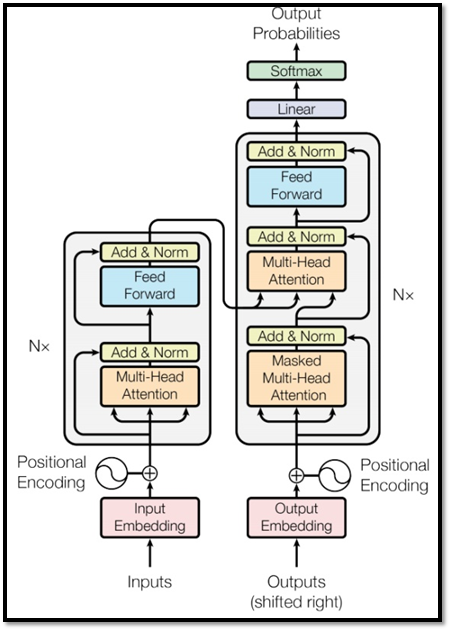
Seq2Seq Model§
输入是一个序列,输出是一个序列,且输出的序列长度由模型来决定
应用场景:
- 语音合成(TTS, Text-to-Speech Synthesis)
- 机器翻译(Machine Translation)
- 语音翻译(Speech Translation)
- 如,直接将英文的音频转换为中文的文本
- 多标签的分类
- 一个类别可属于多个类别,这个时候输出的类别数是不确定的,所以可以用seq2seq的model来确定输出
Encoder§
encoder部分,主要由多头自注意力机制和前馈神经网络构成,输入多少个序列,输出就是多少个序列。
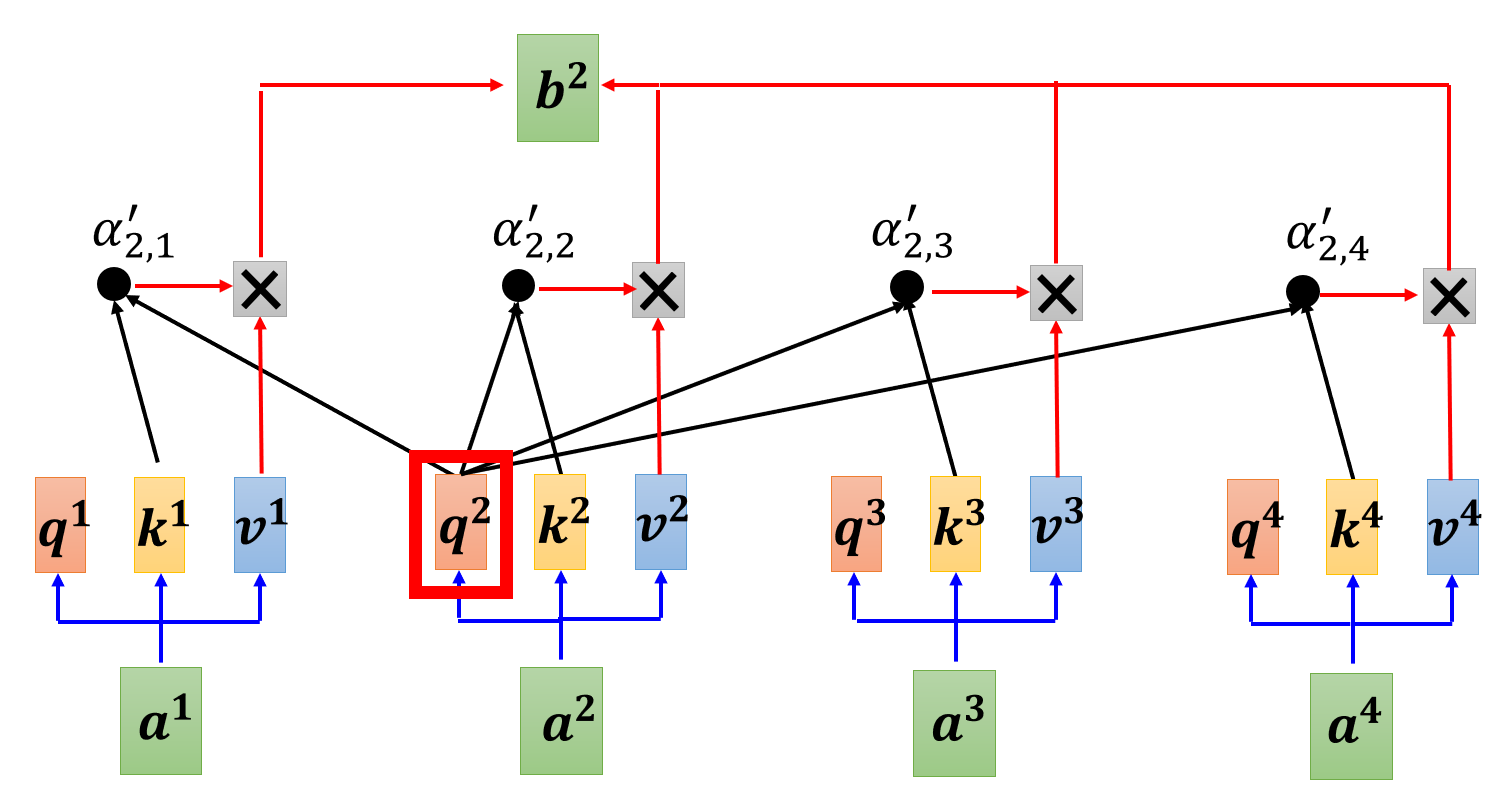
上面是自注意力机制的内部结构,给定一个序列${a^{i}}$,这里以$a^{2}$为例,$a^2$通过乘以一个权重$W$转换为$q^2$,也就是query,然后其他的向量提供$k$(key),由$q$和$k$进行运算(可以进行dot product,也就是点乘,或者进行更加复杂的操作,用以获得相关性),得到$\alpha$值后,通常还会经过一个softmax函数,可以得到序列中每个向量相对于当前的向量的相关度(或者说关注度),最后再由每个$a$来产生一个$v$,与$\alpha$进行加权和,求出$b$。
需要注意的是,这里每次指定的那个向量$a$也是会自己生成$k$然后和自身的$q$进行运算的,包括$v$最后也是参与加权求和。这与后面的decoder部分的cross attention 是不同的,cross attention中当前的向量是不会产生$k$和$v$来参与运算的,只会有自己的$q$与encoder部分的向量的$k$和$v$。
Autoregressive§
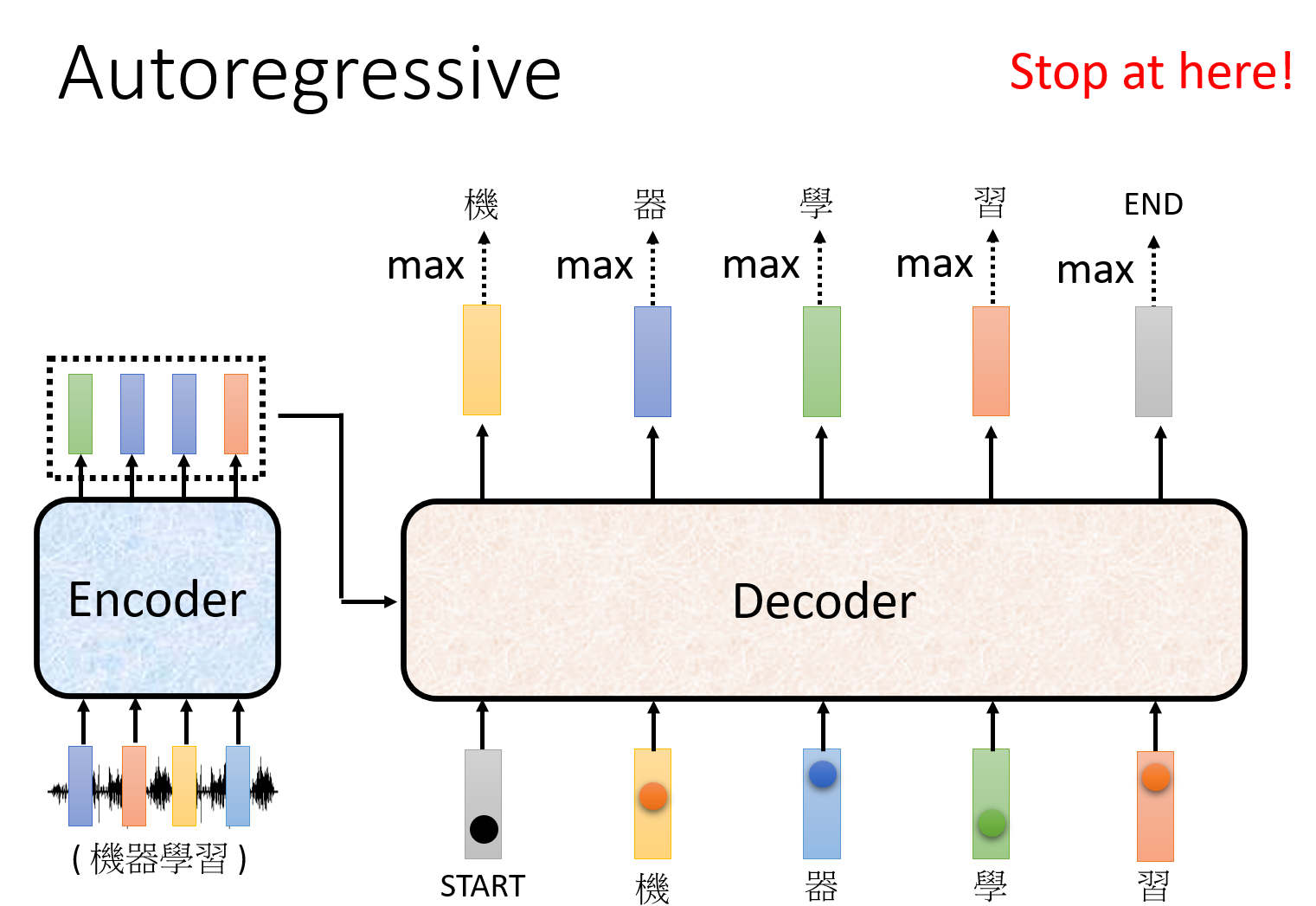
自回归的模型,都是串行的,前一个输出后,再会进行下一个的输入,像之前的RNN、LSTM,就属于是自回归的模型。自回归模型的好处是可以从之前的输入中学到一些信息,但是坏处也是这样如果在之前出现了错误的输出,那么可能就会出现错误的累积。不过,在训练过程中,我们通常不是把前一个的输出给到下一个的输入,只有在实际测试中会这样做,在训练中则会直接把正确的输入依次给到模型。(但也有加入错误输入的方法,Scheduled Sampling,加入噪声可能会得到更好的结果。)
NAT§
相对于自回归的模型而言,非自回归的模型是并行的,同时给定多个输入向量,同时会给出多个输出向量。
- 通过非自回归的方式,可以利用一个额外的分类器来决定输出序列的长度,同时也可以直接控制输出的序列长度。
- 也可以给定一个很长的序列,然后忽视出现<END>后面的序列。
- 并行的方式,速度更快,但是往往得到的效果不如自回归的模型。
Decoder§
Masked Attention§
mask 的 self-attention也就是只考虑本身和之前的向量的关系,不考虑之后的向量。(这是因为encoder的部分是自回归的,所以在逐个输入的时候,是还没有之后的向量的。)
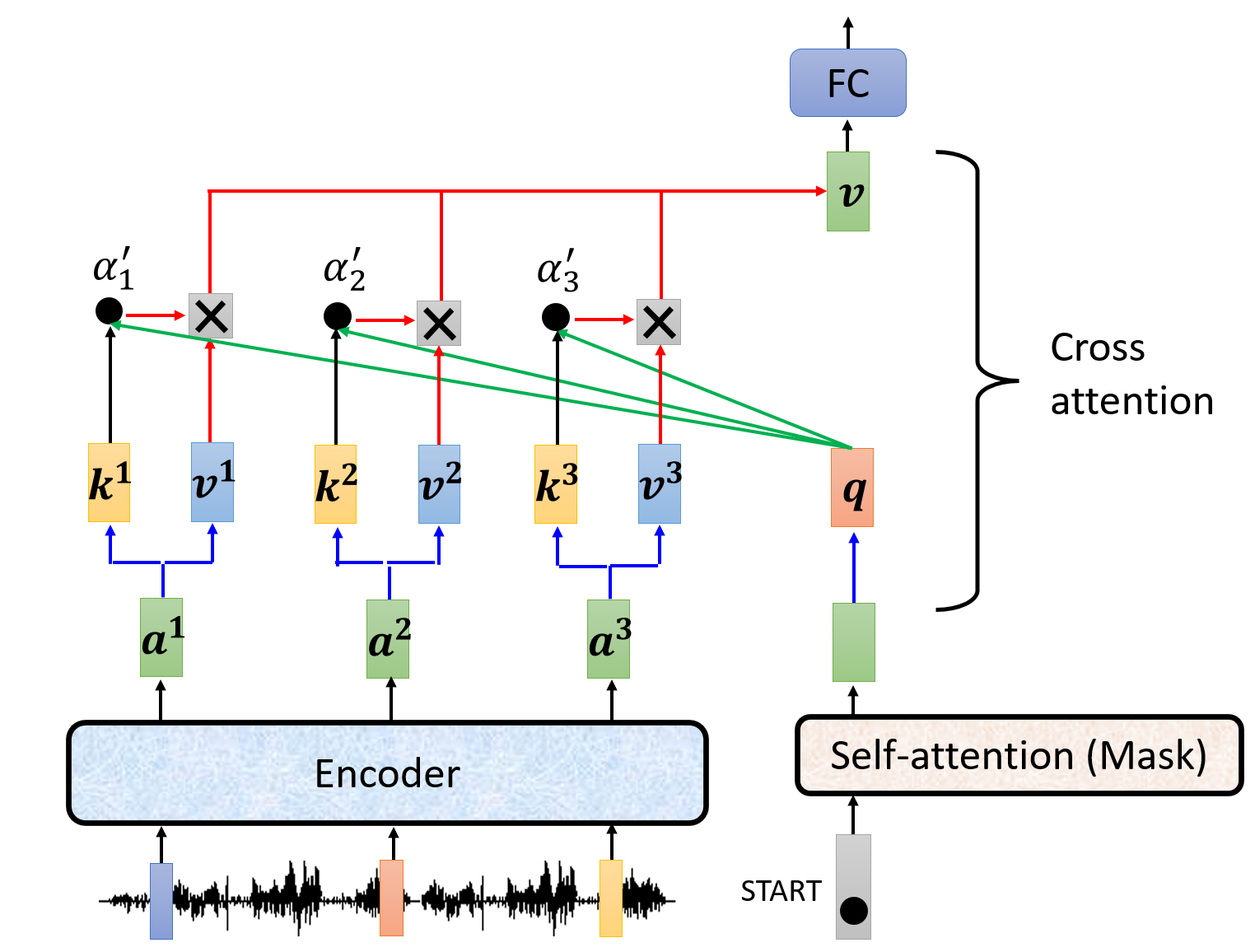
Cross Attention§
经过带mask的self-attention后的输出向量,会转化为$q$,然后与encoder的最后输出的向量得到的$k$和$v$,类似之前的操作,先通过$q$和$k$进行运算得到$\alpha$,再经过softmax函数得到$\alpha^{’}$,最后与$v$进行加权和。
Guided Attention§
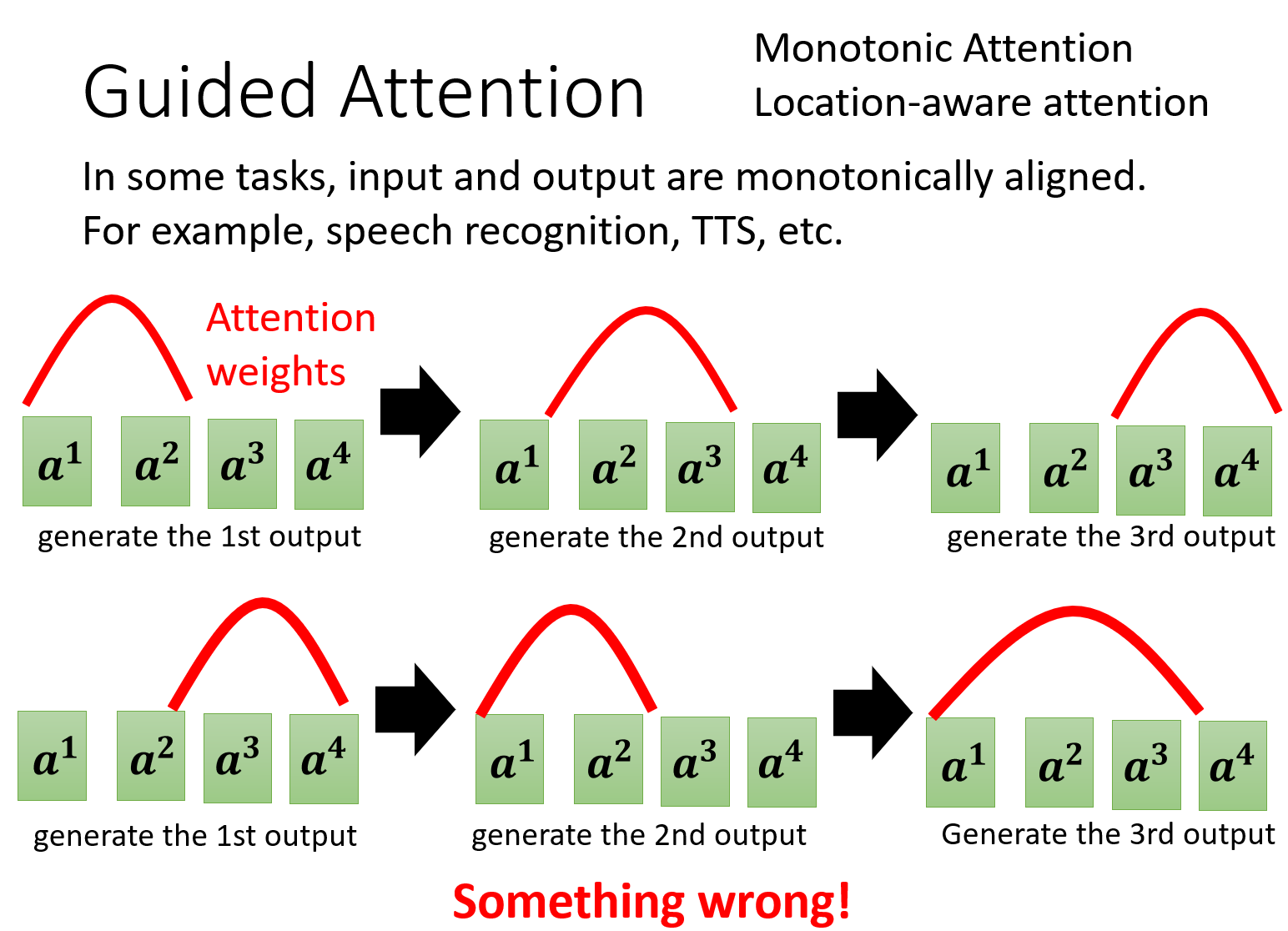
这里不是很理解,但大概就是说模型没有关注到正确的信息,像下面的图中,本来在考虑第一个输出的时候,应该主要认知的是$a^1$和$a^2$,但是在下面的图中却没有去考虑$a^1$,当然这是有争对特定任务的处理方式,当在进行语音辨识的时候,就可能需要依赖这种单调的,往前的关注方式,那么就可以提前进行指导,让他符合这种关注的模式。
调整指导策略:
- Beam Search
- Sampling
Evaluation Metrics§
transformer在训练中,是使用cross-entropy作为损失函数的,但是在进行模型评估的时候,是使用BLEU score来对生成的序列进行评分的,BLEU score越高,也就是评分越高。(这里有说BLEU score没有办法求解梯度,所以没有在训练中使用,但是也可以用强化学习的方式用BLEU score来训练。)
评论