参考链接:
- b站视频:
- 知乎大佬的笔记:对比学习Contrastive Learning综述 - 知乎 (zhihu.com)
第一阶段——百花齐放§
InstDisc§
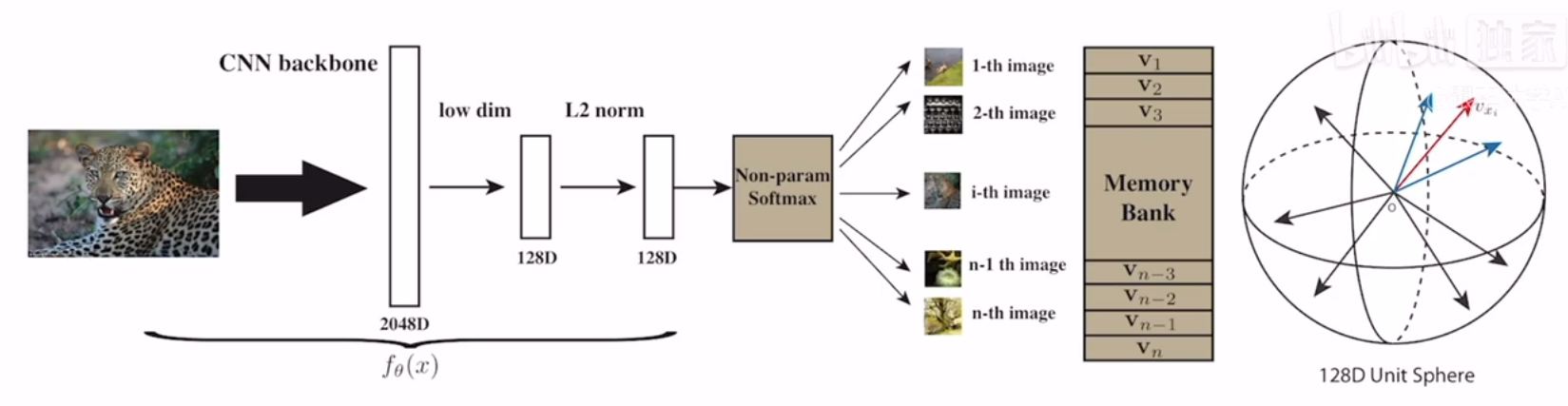
动机:根据有监督学习中的类别分类时,相似的图片会被归为相近的类,可以将每个图片视为一个单独的实例(instance),映射到一个图像的特征空间(这里感觉和nlp中词向量空间类似,相似的话,离得会比较近),从而引出了Instance Discriminate这个概念,可以将每一张图片都能区分开来,每个图片都是自己的类。
方法:通过一个卷积,将一个batch_size为256的图片转换为特征向量后,从memory bank中随机取4096个负样本(memory bank一开始会随机初始化),进行对比学习,从而将对应的256个新的向量更新到对应的memory bank中。
里程碑式的意义:
- NCE loss
- Instance Discriminate
- 提出了memory bank一种新的数据结构构建特征
Invariant Spread§
动机:相似的图片呢,要保持invariant,要尽可能相似;不相似的图片呢,要spreading,要尽可能不同。
方法:正样本是数据增强后的样本,负样本是除了这个batch中的自己本身和数据增强的自己外,剩下的都是负样本,如输入batch为256,负样本数为(256-1)*2,从而可以使用同一个编码器进行端到端的训练,没有像InstDisc中那样使用了额外的数据结构去存储负样本。
前两个任务都是属于 个体判别(Instance Discriminate) 的代理任务
Representation Learning with Contrastive Predictive Coding(CPC)§
生成式的代理任务
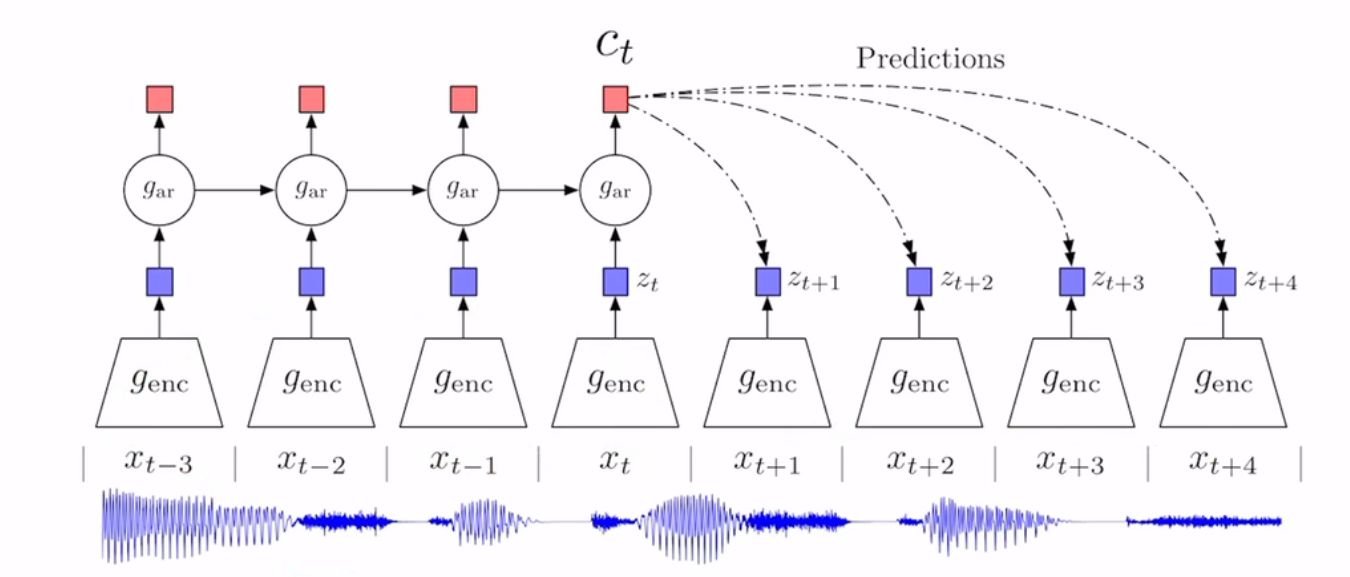
动机:是一个通用的对比学习框架,图像、音频、文本等可以表示为序列的数据都可以
方法:通过对历史的序列利用自回归的模型进行编码,得到一个context features(上下文特征),然后就可以将未来的序列编码后的特征作为对应的正样本,负样本的话则是采用任意选取输入进行编码。编码器+自回归模型
意义:
- 提出了infoNCE
Contrastive Multiview Coding(CMC)§
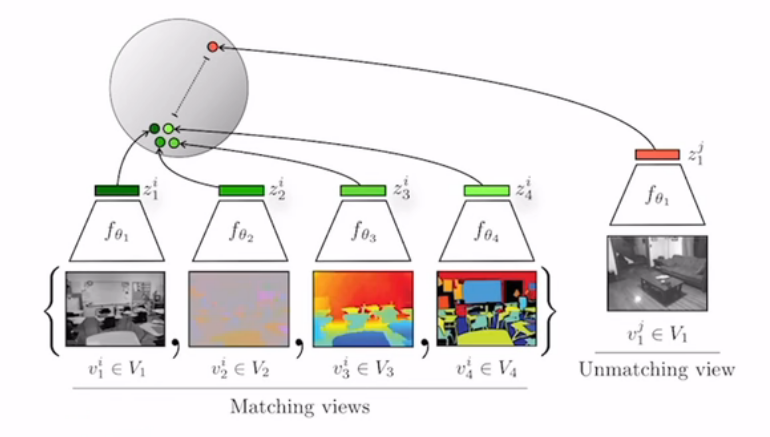
动机:多视角的对比学习,有可能一个视角会有噪声,并不足以表示完整的信息,所以可以通过多视角的方式,通过增强互信息,能够抓住所有视角下的特征。
方法:不同视角(不同传感器/不同模态)的图片应当互为正样本
意义:
- 证明了对比学习的灵活性
- 证明了对比学习可以用于多模态的可行性,激发了后面clip的产生
- 作者用对比学习的方法做了新的蒸馏方法
可能的局限性:
不同的模态的数据可能就需要不同的编码器(但是现在transformer架构是有可能同时处理多个模态),计算代价会高些。
阶段总结§
- 18-19年的论文
- 代理任务有判别式和生成式的
- 使用的损失函数有NCE、infoNCE、以及其他的NCE的变体
- 编码器上,有使用单个的,也有多个的,同时也有使用自回归模型的
CV双雄§
MoCo§
方法:是Inst Disc的改进工作
意义:
- 队列(queue),解决大字典的问题
- 动量编码器(moment),解决字典特征不一致的问题
SimCLR§
方法:Invariant Spreading的改进。通过两个不同的数据增强得到原图像的两个增强后的图像,相当于两个不同的视角,后面的$f$共享参数,例如如果是一个ResNet50,则经过$f$后,输出是为2048维的向量。再后面具有创新性的一点是,增加了一个projection layer,本质上是一个mlp+relu,全连接层加一个激活函数,进行非线性变换,会将2048维降低到128维,然后再进行对比学习,通过这种增加一个projection layer的方式,使得在ImageNet上的精度上升了10%。但是,需要注意的是,这个projection layer只有在训练的时候才使用,在推理中是不再使用的。
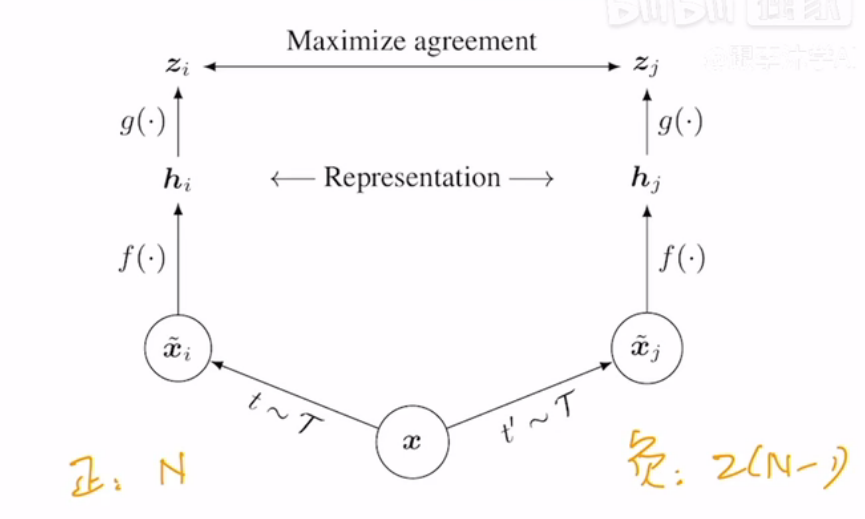
意义:
- 更多更好的数据增强
- 增加的projection layer
- 更大的batch size
MoCo v2§
方法:借鉴了SimCLR的思想,使用了更多更好的数据增强,并增加了projection layer,从而在效果上高于SimCLR,并在训练的成本上远小于SimCLR。
SimCLR v2§
改进:
- 更大的主干模型,ResNet153
- 更深的projection layer,两层
- 使用了MoCo中的动量编码器
SwAV§
方法:
- 采用了聚类的思想
- multiple crop,增加了更大的正样本
CPC v2§
改进:
- 更多的数据增强
- layer norm
infoMin§
在CMC的基础上的改进
- 最小化最大互信息
不用负样本§
Bootstrap Your Own Latent(BYOL)§
方法:输入的图片经过两种不同的数据增强,变为$v$和$v^{’}$,然后上面的编码器和下面的编码器的网络结构是一样的,但参数的更新方式不同,上面的编码器是正常的梯度更新,下面的编码器是随着的上面的编码器的动量更新,类似于之前MoCo的动量编码器。最后上面增加的predition也是一个mlp,他会去预测下面的编码器输出的特征向量,使用的Loss为MSE。(下面的sg代表的是stop gradient,所以下面是不会进行梯度更新)
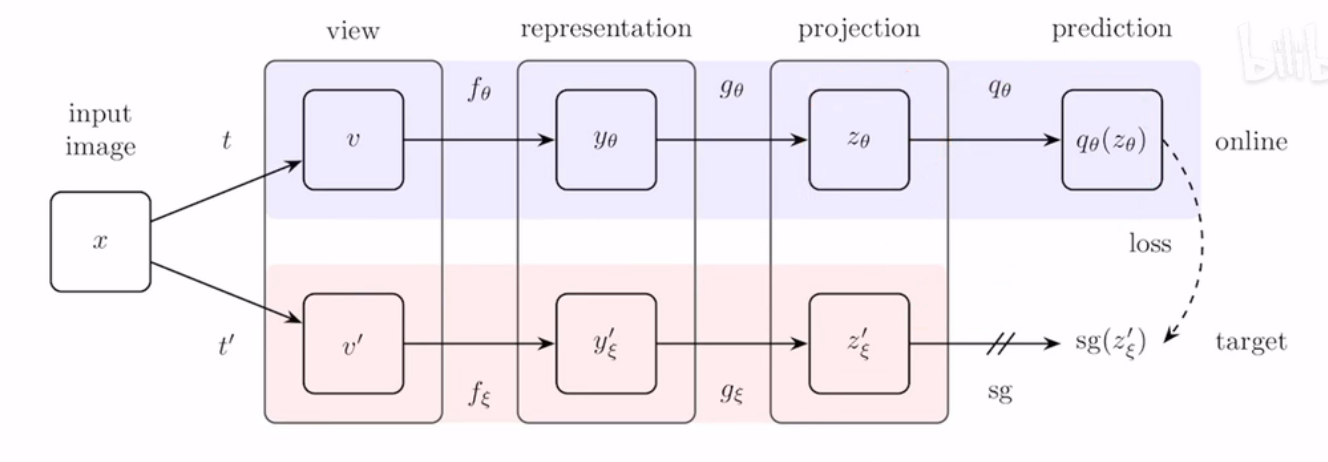
解释:
- 为什么这种不使用负样本的方式不会导致模型的坍塌?
- 这和模型参数的初始化相关,直接的表现于是否在projection、prediction、backbone中使用BN相关
Exploring simple siamese representation learning(SimSiam)§
transformer§
将原resnet的bankbone进行替换
评论