VIT发表于ICLR2021,成功将transformer应用于视觉领域,打破了cv与nlp的壁垒,带动了多模态方向的发展。不过,看了讲解视频后,按论文中所说,transformer结构是本来就有的,patch的方法是2020年有人提出的,位置编码和分类上用也是BERT的方法,感觉还真看不出来有啥创新的,但是却很关键的是将transformer用在cv上work了起来,而且效果还特别好,还值得关注的一点是论文中真的是做了大量的实验,这可不是一般的量级。
Vision Transformer理解§
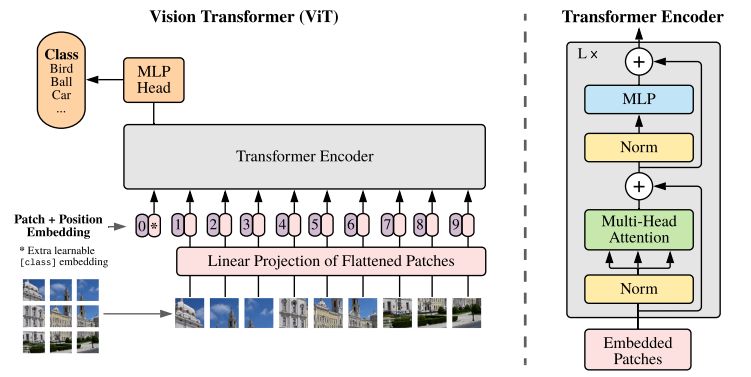
一、将transformer用于图像上存在的问题§
- 序列太长,复杂度过高。在transformer中需要输入序列,每个序列中又有很多的向量,如果要将图像直接输入到transformer中,则需要像全连接层那样将图像展平,但是这样的话,如果是224x224大小的图片,将每个像素展开为序列的话,则展开的序列长度会变为50176,而且朴素的transformer中的attention metrics还是$O(N^2)$,这样的复杂度就非常夸张了,即使是在BERT中,输入的序列长度是512(PS:其实也并不是说一定不能超过512,一方面是因为超过512后复杂度确实太高,另一方面是BERT中的positional encoding是经训练得到的,如果使用预训练权重则就无法直接超过512,这篇文章有解释为什么最长512,以及如何可以超过512的方法:BERT模型输入长度超过512如何解决? - 知乎 (zhihu.com))。
为了解决图像上向量太长的问题,在先前的使用transformer用于cv的研究中,有使用与卷积结合的方式,来减小图像大小,再转为向量给到transformer;也有和vit类似的工作,将图像预处理为一个个patch,以patch为局部向量,不利用卷积,直接输入给transformer。类似于下面的操作:
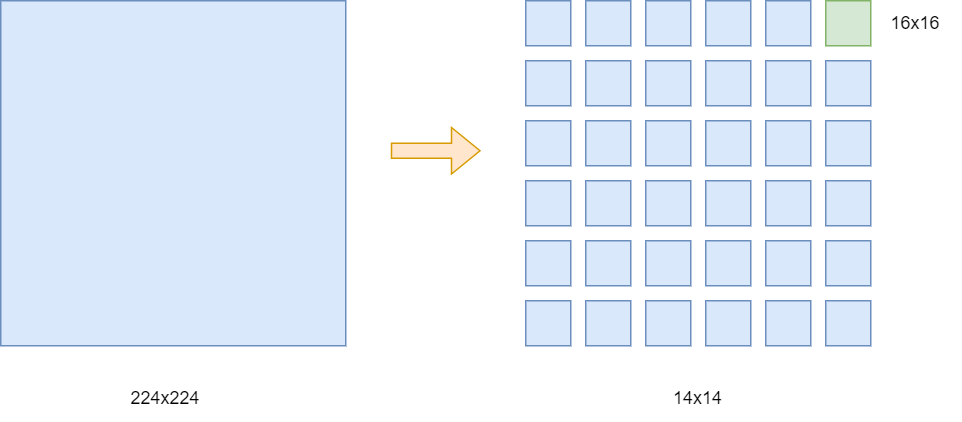
将224x224的图像拆分为14x14个patch,每个patch的大小为16x16,这样输入的序列长度就变为了14x14=196,而其中的每个向量长度则为16x16x3=768,3为三通道,远小于之前的长度。
二、输入的向量与在nlp中transformer的输入有什么区别?§
- 图像转为patch的预处理操作
- positional encoding的处理上的不同,在vit的论文中有提及使用了三种位置编码的方式,最终效果来说,直接使用一维的位置编码即可
- 第一种方式,也是主要使用的,1D的可学习位置编码, 可以自上而下、自左而右来给每个patch编号,对应的编号并不是单纯的数字,而是一个长度与token长度一样的向量,然后会直接加到序列的向量上,从而添加位置信息。这种方法和BERT中的位置编码方法是一样的。
- 第二种方式,使用2D的可学习位置编码,假如之前一维的是1,2,3这样的,那么二维的就是11,12,13,21,22这样的,有行和列号,当然这里也并不是直接是数字,而是对应的向量,假设之前的位置向量长度为d,则现在的二维的每个token会有对应的两个长度为d/2的位置向量,也就是行和列,之后再拼接回去也是d。
- 第三种方式,使用相对位置编码,offset的方式。
主要的区别只有上面的两点,在输入给transformer之前还会经过一个全连接层,如果输入的图片大小为224x224的话,则按之前所说会有14x14个16x16大小的patch,也就是196x(16x16x3) = 196x768,196是序列长度,768是向量的长度,经过的全连接层也是768x768的,也就是输入输出大小不变。当然也是可以修改的,只有对全连接层的输入和输出修改即可。
三、使用卷积和transformer会有哪些区别?§
直观上来看,给到transformer的图像被拆分成了很多小patch,卷积操作的话也是使用卷积核每次对部分特征进行提取,这样的话,看起来卷积和transformer都是对局部特征进行了处理。
但不同的地方在于:
- 卷积中,会有同一个卷积核对图像中的不同局部位置进行卷积,按论文中说的,卷积操作是能够得到先验经验和归纳偏置,换句话说,就是使用卷积会更容易在中小数据集上训练起来,而transformer因为不存在这样的特点,所以会需要更多更大型的数据集才能够训练的起来。
- 这里卷积所说的归纳偏置,解释上就是CNN的inductive bias应该是locality和spatial invariance,即空间相近的grid elements有联系而远的没有,和空间不变性(kernel权重共享)。
- 在论文中的实验中也同样表明了这一点,在中小数据集上,明显卷积是优于transformer的,但是在大型数据集上,transformer的优势就凸显出来了,而且训练所需的代价也会相较来说会更小一些。
四、VIT中使用的特殊字符[CLS]§
同样和BERT类似,在我们使用BERT来进行分类任务的时候,我们通常会使用特殊字符[CLS]的输出向量作为当前整个序列的特征,然后给到一个分类器进行分类,在VIT中也是这样,会额外的增加一个[CLS],然后再给到transformer,比如一开始图像经预处理后得到的大小是196x768的序列向量,然后此时会再增加一个1x768的向量,这样就会有197x768作为transformer输入。
在论文中也有提及可以不使用[CLS],而使用GAP(Global Average Pooling),如对于196x768的输出,再经过一个全局平均池化的话,就可以变为1x768的向量,同样可以作为整个序列的向量特征,但是要注意的是使用[CLS]和GAP两种方法所需要的参数并不一样,文中给出的实验对应的学习率就会有差异。
五、fine-tune时若由于图像大小变化导致patch个数发生变化从而序列长度变化怎么办?§
图像大小的变化导致存在的问题:
- 和BERT中类似,一般说BERT序列长度最长为512,在VIT中也会存在这样的限制,因为位置编码都是训练出来的,如果使用预训练的权重,那么超出原本训练的序列长度的部分自然是没有之前学习到的位置编码信息的。
为了解决上面说的问题,VIT中提出的临时解决的方法是插值法,但是这样也同样是会带来表现能力的下降。
- 插值法(pytorch中有内置函数)
评论